Deep Learning(딥러닝) - Model설계 기초
딥러닝 - 모델 : 특정구조로 만들어진 인공지능 객체
모델 설계
- 활성화 함수 : 각 노드에서 계산된 값을 다음층으로 전달하기 전에 비선형 변환을 적용하는 함수
- 손실함수 : 딥러닝 모델의 예측값과 실제값 사이의 차이를 측정하는 함수이며, 모델이 얼마나 정확하게 예측하는지를 나타내는 지표
- 최적화 함수 : 딥러닝 모델이 학습과정에서 손실함수를 최소화(0과 가깝게 줄이기위해)하여 모델의 성능을 향상 시키는데 사용
# TensorFlow 라이브러리 안에 있는 Keras API에서 필요한 함수들을 불러옵니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 데이터를 다루는 데 필요한 라이브러리를 불러옵니다.
import numpy as np
# 준비된 수술 환자 데이터를 불러옵니다.
Data_set = np.loadtxt("../data/ThoraricSurgery3.csv", delimiter=",")
# delimiter : 구분자
X = Data_set[:, 0:16] # 환자의 진찰 기록을 X로 지정합니다. (모든 행 사용: 0~16열 사용)
y = Data_set[:, 16] # 수술 후 1년 후 사망/생존 여부를 y로 지정합니다. (인덱스 16만 사용)
# 딥러닝 모델의 구조를 결정합니다.
model = Sequential() # 딥러닝 구조를 짜고 층을 설정하기 위해 사용
# 입력 & 은닉층
model.add(Dense(units=30, input_dim=16, activation='relu'))
# 출력층
model.add(Dense(units=1, activation='sigmoid'))
# 딥러닝 모델 실행
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 학습
history = model.fit(X, y, epochs=5, batch_size=16)model.add(Dense(30, input_dim = 16, activation='relu'))
# 입력 & 은닉층
# 30 : input_dim 16개의 차원을 입력하여 30개의 노드로 보낸다.
# relu : 0보다 작으면 0, 0보다 크면 입력값을 받는다. / 계산효율성이 높아 학습속도가 빠르다는 장점을 가지고 있다.model.add(Dense(1, activation = 'sigmoid'))
# 출력층
# 노드 1개 : 출력 값을 하나로 정해서 보여줘야 하므로
# sigmoid : 0과1의 이진분류에 특화 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# loss (손실함수)
# binary_crossentropy : 이진교차 엔트로피 (정수 0과 1로 나누어진 이진분류 문제에서 사용되는 손실함수)
# optimizer ( 최적화함수)
# adam : 최적화 함수에서 가장 보편적이고 성능이 좋은 함수
# accuracy : 정확도 history = model.fit(X, y, epochs=5, batch_size=16)
# 모델 학습 (모델 실행)
# epoch(에포크) : 학습 프로세스가 모든 샘플에 대해 한번 실행되는 것
# batch_size : 샘플을 한번에 몇개씩 처리할지 정하는 부분 => 학습화된 데이터 업데이트 주기 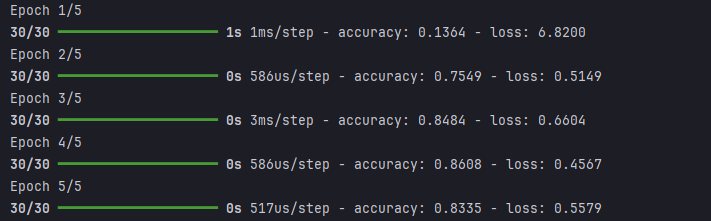
사진 설명을 입력하세요.
* numpy : 수치연산을 빠르고 효율적으로 수행하기 위해 사용됨
- 다차원 배열을 제공하고, 배열연산 등... 수학적 연산을 지원
11장
데이터 다루기
* pandas : 데이터 분석 및 조작을 위한 라이브러리
- 데이터 정렬, 필터링, 그룹화 , 통계 분석 등... 다양한 데이터 분석 기능을 제공
* DataFrame 특징
- 2차원 테이블 형태의 데이터 구조
- 각 열은 다른 데이터 타입을 가질 수 있다. (숫자, 문자열, 날짜 등)
- 행과 열에 레이블(index, column)을 지정할 수 있어 데이터 식별 및 접근이 용이합니다.
- 누락된 데이터 처리, 데이터 정렬, 데이터 병합 등 다양한 데이터 조작 기능을 제공합니다.
* Numpy 와 Pandas 차이
NumPy의 Data는 수치 연산에 최적화된 구조로, 빠른 연산이 필요한 과학 계산이나 머신 러닝에 적합합니다. 반면 pandas의 DataFrame은 데이터 분석에 필요한 다양한 기능과 유연한 데이터 구조를 제공하여 데이터 조작 및 분석에 용이합니다.
즉, 데이터 분석 작업에서 NumPy의 Data를 사용하여 데이터를 효율적으로 처리하고, pandas의 DataFrame을 사용하여 데이터를 분석하고 시각화하는 등의 작업을 수행하는 것이 일반적입니다.
판다스를 활용한 데이터 조사
출처 입력
df.head(5);
# 데이터의 첫 다섯 줄을 불러오겠다
df["diabetes"].value_counts()
# 각 컬럼의 값이 몇 개씩 있는지 알려준다
df.describe()
# 정보별 샘플 수(count), 평균(meta), 표준편차(std), 최솟값(min), 백문위수로 25%, 50%, 75%에 해당하는 값
# 그리고 최댓값(max)이 정리되어 출력
df.corr()
# 각 항목이 어느정도 상관관계를 가지고 있는지 알고 싶을 때 사용
수치를 표(table)형태로 보여줌 df.corr()
=> 열(속성) 간의 상관관계를 계산하여 상관계수 행렬을 반환하는 함수
=> 1에 가까울 수록 항목의 상관도가 높다
=> 데이터 속성 간의 상관관계를 파악하면 데이터 분석 및 모델링에 유용한 정보를 얻을 수 있다
피마 인디언 당뇨병 예측 실행
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# pandas 라이브러리를 불러옵니다
import pandas as pd
df = pd.read_csv("../data/pima-indians-diabetes3.csv")
X = df.iloc[:,0:8] # 세부정보를 X로 지정
y = df.iloc[:,8] # 당뇨병 여부를 y로 지정
# 모델 설정
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu', name='Dense_1'))
model.add(Dense(8, activation='relu', name='Dense_2'))
model.add(Dense(1, activation='sigmoid', name='Dense_3'))
model.summary()
# 모델 컴파일
model.compoil(loss='binary_crossentropy', optimizer='adam')
# 모델 실행
history = model.fit(X, y, epochs=100, batch_size=5)=> 은닉층을 추가 : 은닉층을 몇층으로 할지, 은닉층의 안의 노드는 몇 개로 할지에 대한 정답은 없다.
자신의 프로젝트에 따라 결정해야한다. 여러 번 반복하면서 최적 값을 찾아내는 것이 좋으며, 노드 수와 은닉층의 개수를 바꾸어 보면서 더 좋은 정확도를 찾아야 한다.
model.summary()
# 모델의 구조를 요약해서 보여주는 함수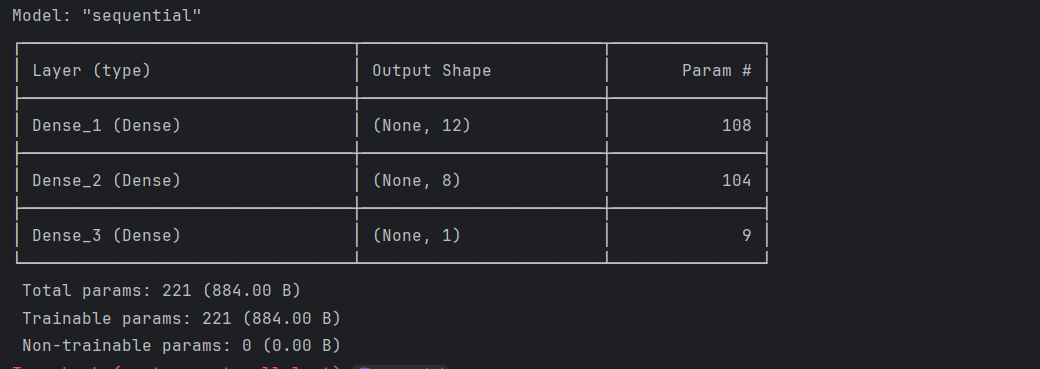
사진 설명을 입력하세요.
=> Param : 각 층에 있는 학습 가능한 파라미터 수 ( 각 층에서 가중치와 편향의 개수를 합한 값)
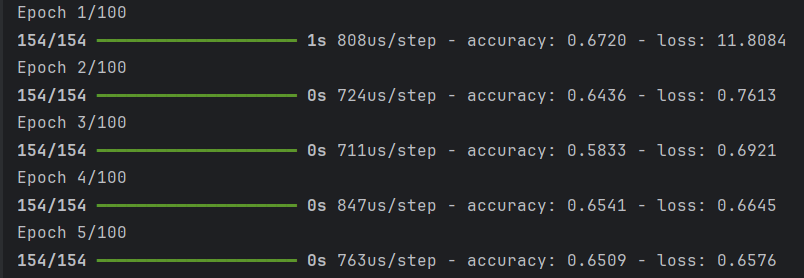
사진 설명을 입력하세요.
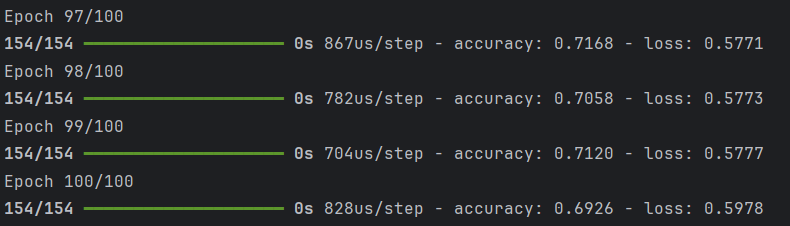
사진 설명을 입력하세요.
=> 100번을 반복한 현재, 약 71.61%의 정확도